The Pipeline
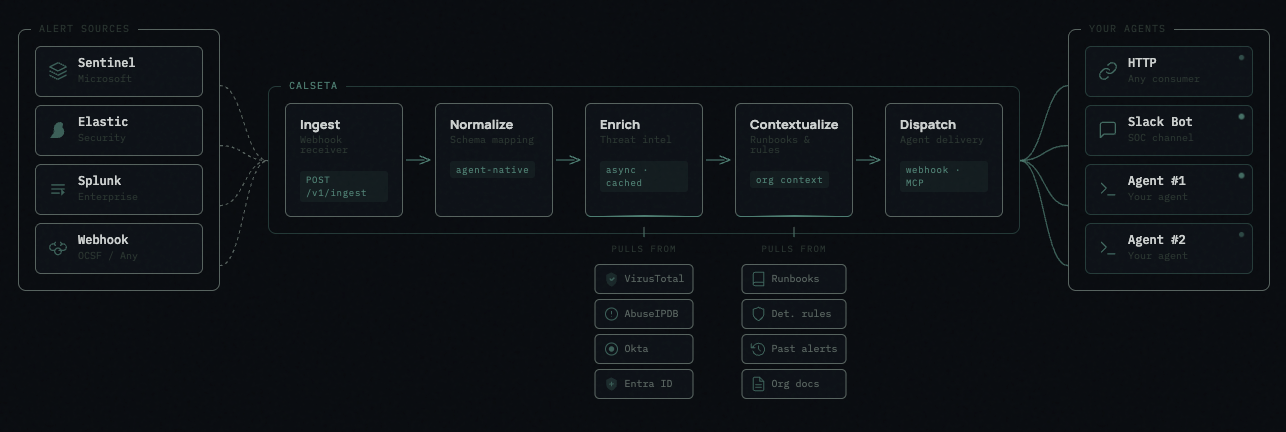
1. Ingest
Alerts arrive via webhook atPOST /v1/ingest/{source_name}. Each source integration validates the raw payload and hands it off to normalization. The endpoint returns 202 Accepted within 200ms — all downstream processing is async.
Supported sources: Microsoft Sentinel, Elastic Security, Splunk, Generic webhook.
2. Normalize
All alerts are normalized to Calseta’s agent-native schema — clean field names designed for AI consumption (title, severity, occurred_at, source_name). Source-specific fields that don’t map are preserved in raw_payload. Normalization happens synchronously at ingest time.
Calseta uses its own schema optimized for agent consumption, not OCSF. OCSF is designed for data producers mapping to SIEMs. Calseta’s schema gives agents readable field names, structured enrichment data, and a relational indicator model.
3. Enrich
Threat indicators extracted from the alert (IPs, domains, file hashes, URLs, accounts) are enriched by all configured providers in parallel. Results are cached with provider-specific TTLs. A slow or failing provider never blocks others. Indicator extraction runs in three passes:- Source plugin — hardcoded extraction logic per source
- System mappings — normalized field mappings (pre-seeded)
- Custom mappings — user-defined per-source field mappings against
raw_payload
(type, value). Each unique indicator is a global entity — the same IP across 50 alerts is one indicator row with enrichment results, linked to all 50 alerts.
4. Contextualize
Relevant organizational documents are attached to the alert based on targeting rules. Documents can be global (always included) or targeted to specific alert types, severities, source names, or detection rules. Context includes: runbooks, IR plans, SOPs, detection rule documentation, and workflow documentation.5. Dispatch
Once enrichment is complete, the enriched alert payload is dispatched to registered agents via webhook. The payload includes everything an agent needs:Architecture
